
Определение и анализ нагрузки на Linux-системы
Введение
Для администраторов серверов критически важно уметь оперативно диагностировать причины повышенной нагрузки на систему. Понимание того, какие ресурсы исчерпаны и какие процессы создают нагрузку, позволяет принимать обоснованные решения: оптимизировать работу сервисов или масштабировать ресурсы.
В этой статье рассмотрим практические методы диагностики.
Ключевые утилиты для мониторинга
Базовый мониторинг системы
Утилита top одна из основных утилит для мониторинга системы и процессов в реальном времени в Linux/Unix-системах.
Чтобы запустить её, достаточно в терминале набрать команду top:
root@server:~# topПри запуске top экран делится на две основные части:
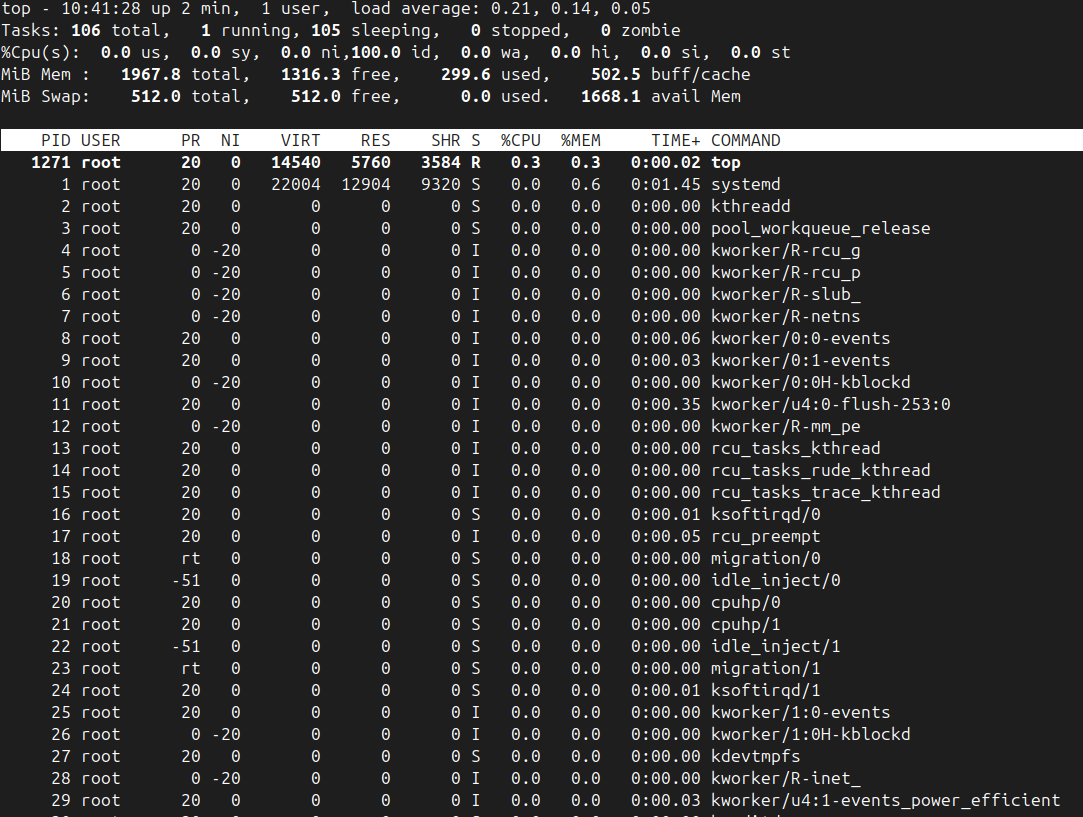
- Сводка системы (верхние строки):
- Первая строка:
-

- Текущее время.
- Время работы системы (uptime).
- Число пользователей (user).
- Load average (средняя нагрузка) за 1, 5 и 15 минут — ключевой показатель! Означает среднее количество процессов, ожидающих в очереди на выполнение. Правило: если значение больше количества ядер CPU — система перегружена (но для однопоточных приложений высокие значения могут быть нормой).
-
- Вторая строка:
-

- (Tasks): Общая информация о процессах: общее число
- Работающие (running)
- Спящие (sleeping)
- Остановленные (stopped)
- Процессы-зомби (zombie). Zombie-процессы (не убираемые родителем) в небольшом количестве — норма, но если их число растет — это проблема.
-
-
Третья и четвертая строки (ЦПУ — %Cpu(s)):
-

-
us — пользовательские процессы.
-
sy — процессы ядра.
-
id — простой (idle). Низкий id (менее 10-20%) — признак высокой нагрузки на CPU.
-
wa — ожидание ввода-вывода (I/O wait). Высокий wa (более 5-10%) — указывает на "бутылочное горлышко" ввода-вывода (медленный диск, высокая сетевая активность).
-
hi, si — прерывания.
-
st — "виртуальному ЦПУ" не дали время (актуально для виртуальных машин).
-
-
Пятая и шестая строки (Память — KiB Mem / Swap):
-

-
Показывает использование оперативной (Mem) и swap-памяти.
-
Важно смотреть на доступную память (avail Mem) и использование swap (used Swap).
-
Активное использование swap при свободной оперативной памяти — нормально (ядро кэширует).
-
Активное использование swap при малой свободной RAM — признак нехватки памяти, система начинает "тормозить".
-
-
- Первая строка:
-
Таблица процессов (нижняя часть):
-

-
Список процессов, сортированный по умолчанию по убыванию нагрузки на ЦПУ.
-
PID — идентификатор процесса.
-
USER — владелец процесса.
-
PR / NI — приоритет (Priority / Nice).
-
VIRT — виртуальная память (вся память, включая своп и библиотеки).
-
RES — резидентная память (физическая RAM, используемая процессом). Показывает реальное потребление "оперативки".
-
SHR — разделяемая память (библиотеки и др.).
-
%CPU — загрузка ЦПУ процессом.
-
%MEM — доля физической памяти, используемая процессом.
-
TIME+ — общее время работы процесса на ЦПУ.
-
COMMAND — имя команды.
-
-





На что обратить внимание при нагрузке (поиск проблем)
- Load average: Сравнить с числом ядер CPU (lscpu или нажмите 1 в top).
- %CPU idle (id): Если близок к 0% — процессор загружен полностью.
- I/O wait (wa): Высокое значение — система ждет медленного диска/сети.
- Процессы-зомби (zombie): Много зомби — ошибка в программе.
- Память: Мало avail Mem и растет used Swap — нехватка RAM.
- В таблице процессов: Искать процессы с высокими значениями %CPU, %MEM или RES. Это "виновники" нагрузки.
Основные клавиши управления (интерактивные команды)
- Сортировка и поиск:
- P (по умолчанию) — сортировка по использованию ЦПУ (%CPU).
- M — сортировка по использованию памяти (%MEM).
- N — сортировка по PID (номеру процесса).
- T — сортировка по времени работы (TIME+).
- R — обратный порядок сортировки (toggle).
- L или & — поиск по имени процесса. Вводите строку.
-
Отображение информации:
-
1 (цифра) — показать нагрузку на каждое ядро ЦПУ отдельно.
-
t — переключить отображение строк CPU (график/текст/скрыть).
-
m — переключить отображение строк памяти (график/текст/скрыть).
-
u — показать процессы только конкретного пользователя. Введите имя.
-
Shift + H — показать/скрыть потоки (threads). Важно для многопоточных приложений.
-
c — показать полную команду с аргументами.
-
Shift + V — включить древовидный режим отображения иерархии процессов.
-
x или y — подсветка столбца сортировки и активного процесса.
-
-
Управление процессами:
-
k — убить (kill) процесс. Запросит PID и сигнал (по умолчанию 15 — SIGTERM, "вежливое" завершение).
-
r — изменить приоритет (nice) процесса. Запросит PID и значение nice (от -20 до 19, чем меньше, тем выше приоритет, требуется права root для отрицательных значений).
-
-
Прочие команды:
-
Space или Enter — немедленное обновление.
-
s — изменить интервал обновления (delay) в секундах (например, 2.0 или 0.5).
-
Shift + W — сохранить текущие настройки отображения в файл ~/.toprc (будут загружаться при каждом запуске).
-
h или ? — справка по всем командам.
-
q — выйти из top.
-
Мониторинг использования памяти
Можно посмотреть утилитами free и vmstat.
Запуск командой в терминале free -h:
free -hВывод команды будет примерно следующим:

Команда vmstat 2 5 будет выводить 5 отчетов (второе число) с интервалом в 2 секунды (первое число), показывая статистику по процессам, памяти, подкачке, дискам, CPU и прерываниям:
vmstat 2 5Вывод команды будет примерно следующим:

Важные колонки:
- swpd - используемый объем swap
- si/so - swap-in/swap-out (если > 0 - нехватка RAM)
Анализ дисковой подсистемы
Утилита iostat — это ключевая утилита из пакета sysstat в Linux, которая собирает и отображает статистику по использованию ресурсов, в первую очередь — загрузке процессора (CPU) и дисковому вводу-выводу (I/O).
Возможно для пакета iostat необходима будет установка, сделать это можно следующими командами:
apt install sysstat -yПосле установки можно выполнить команду iostat -dx 2:
iostat -dx 2Непрерывный мониторинг расширенной статистики ввода/вывода (I/O) для всех блочных устройств, обновляя данные каждые 2 секунды.
Вывод команды будет примерно следующим:

- %util - загрузка устройства (близко к 100% - диск перегружен)
- await - среднее время ответа (норма: < 10 мс для SSD, < 20 мс для HDD)
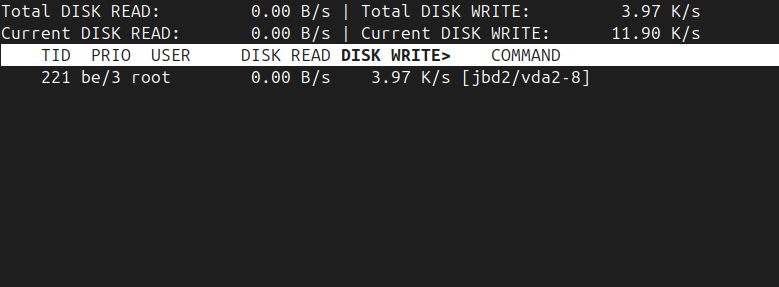
Возможно для пакета iotop необходима будет установка, сделать это можно следующими командами:
apt install iotop -yПосле установки можно выполнить команду iotop -o:
iotop -oКоманда отобразит только тех процессов или потоков, которые в данный момент активно выполняют операции ввода-вывода (I/O), скрывая при этом бездействующие процессы:
Анализ сетевой активности
Утилита nethogs обеспечивает мониторинг использования пропускной способности сети в режиме реального времени с группировкой по процессам или приложениям.
Устанавливаем:
apt install nethogs -yИ затем запускаем в терминале командой nethogs:
nethogsПосле запуска интерфейс отображает столбцы PID, User (Пользователь), Program (Программа), Device (Устройство), Sent (Отправлено) и Received (Получено) с данными об использовании пропускной способности в реальном времени:

Утилита iftop (interface top) отслеживает и отображает использование пропускной способности сети в режиме реального времени на указанном сетевом интерфейсе.
Устанавливаем следующей командой:
apt install iftop -yЗапуск мониторинга будет следующей командой:
iftop -i ens3Если вышла ошибка, то вместо ens3 возможно будет необходимо указать другой внешний сетевой интерфейс, узнать какой Вам нужен интерфейс можно командой:
ip address showВывод будет следующим:
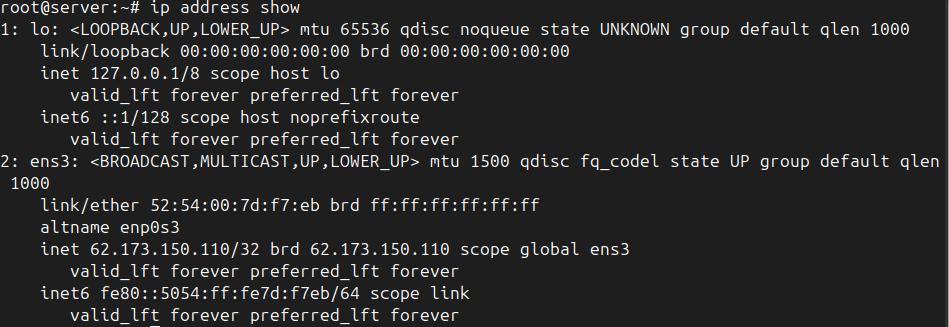
Там где будет указан внешний ip адрес и будет необходимый нам сетевой интерфейс.
Далее запускаем утилиту iftop:
iftop -i ens3Вывод команды будет следующим:
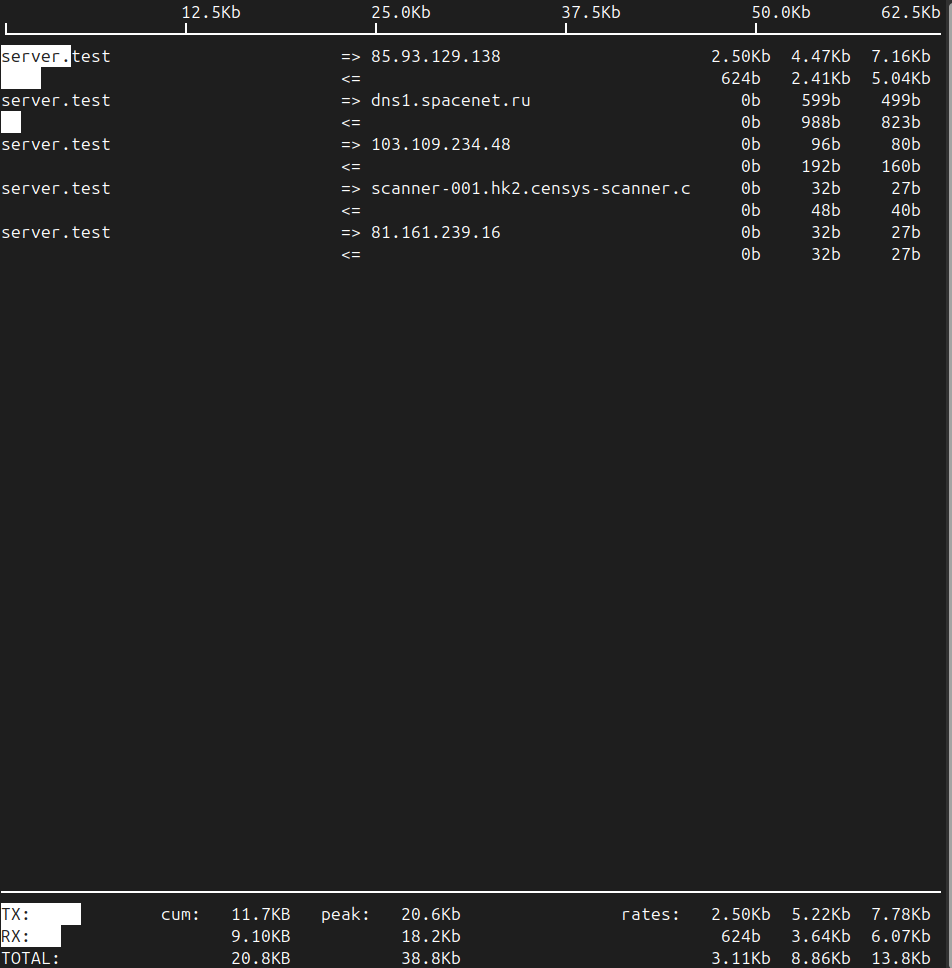
- RX: Полученный трафик (входящий)
- TX: Переданный трафик (исходящий)
- TOTAL: Сумма всего трафика
- PEAK: Пиковое наблюдаемое использование пропускной способности
- Cumulative (cum): Общий объем данных, переданных с момента запуска программы.
Диагностический алгоритм при высокой нагрузке
Определяем тип нагрузки
- Смотрим load average:
- Значение больше количества ядер CPU указывает на очередь процессов
- Высокий load при низком %CPU может означать ожидание I/O
- Анализируем метрики:
- Высокая %CPU + высокий load = проблема с процессором
- Высокая нагрузка на память + активный swap = нехватка RAM
- Высокий %util в iostat = проблема с диском
Идентифицируем проблемные процессы
- Используем top/htop для первичного анализа
- Уточняем тип нагрузки:
- pidstat 2 - детальная статистика по процессам
- ps aux --sort=-%cpu | head -10 - топ-10 процессов по CPU
- ps aux --sort=-%mem | head -10 - топ-10 процессов по памяти
Глубокий анализ проблемных процессов
Для CPU:
perf top
strace -cp <PID> # анализ системных вызововДля памяти:
pmap -x <PID>
cat /proc/<PID>/smaps # детальная карта памяти процессаРешения в зависимости от типа нагрузки
Высокая загрузка CPU
Симптомы: load average > количества ядер, %CPU близок к 100%
- Возможные причины:
- Неоптимизированный код приложения
- Бесконечные циклы
- Cryptographic операции
- Обработка большого объема данных
- Действия:
- Анализ стека вызовов: perf record -g -p <PID>
- Проверка на наличие deadlock-ов
- Оптимизация запросов БД (если приложение базируется на базе данных)
- Масштабирование: увеличение количества ядер CPU, вертикальное масштабирование
Нехватка оперативной памяти
Симптомы: высокое использование swap, процессы завершаются OOM-killer
Анализ:
cat /proc/meminfo | grep -E "(MemTotal|MemFree|Cached|SwapTotal|SwapFree)"Вывод команды:

Действия:
- Оптимизация настроек приложений (например, кэширования)
- Выявление утечек памяти с помощью valgrind
- Настройка swappiness: sysctl vm.swappiness=10
- Масштабирование: увеличение объема оперативной памяти
Высокая нагрузка на дисковую подсистему
Симптомы: высокий %util в iostat, большие значения await
Анализ:
iotop -oPa # покажет процессы с наибольшей дисковой активностьюДействия:
- Оптимизация запросов к базе данных (индексы, запросы)
- Настройка кэширования
- Перераспределение нагрузки между дисками
- Использование tmpfs для временных файлов
- Масштабирование:
- Переход на SSD/NVMe
- Использование RAID-массивов
- Увеличение количества дисков
Сетевая нагрузка
Действия:
- Оптимизация размера передаваемых данных
- Кэширование статического контента
- Балансировка нагрузки между серверами
Как остановить (завершить) процесс
Есть два основных способа прямо в top:
Клавиша k (рекомендуемый способ):
- Нажмите клавишу k.
- Введите PID процесса (первая колонка), который нужно завершить.
- Программа запросит номер сигнала. Нажмите Enter для отправки сигнала по умолчанию (SIGTERM = 15), который позволяет программе корректно завершиться.
- Если процесс не реагирует, повторите шаги, но в качестве сигнала укажите 9 (SIGKILL). Это жесткое, немедленное завершение без возможности "прибраться" за собой.
Клавиша r (изменение приоритета, может косвенно помочь):
- Менее распространено для остановки, но если снизить приоритет (nice) "прожорливого" процесса, система будет больше ресурсов отдавать другим задачам.
Важно: Для отправки сигналов SIGKILL (9) или изменения nice на отрицательные значения обычно требуются права суперпользователя (root).
Профилактика и постоянный мониторинг
Настройка сбора статистики
# Установка и настройка sysstat для сбора исторических данных
apt install sysstat
# Настройка в /etc/default/sysstat (активировать сбор)Полезные команды для автоматизации
# Создание дампа процессов при высокой нагрузке
ps auxf > /tmp/high_load_$(date +%Y%m%d_%H%M%S).log
# Мониторинг в фоне с записью в файл
vmstat 5 12 > /var/log/vmstat.logРекомендуемые инструменты для постоянного мониторинга
- Для standalone-серверов: Netdata, Zabbix-agent
- Для кластеров: Prometheus + Grafana, Elastic Stack
- Логирование: rsyslog, journalctl с персистентным хранением
Заключение
Эффективное управление нагрузкой на Linux-серверах требует системного подхода. Начинайте с оперативной диагностики базовыми утилитами, углубляйтесь в анализ проблемных процессов, и только после тщательного анализа принимайте решение об оптимизации или масштабировании. Регулярный мониторинг и сбор исторических данных позволят не только оперативно реагировать на проблемы, но и прогнозировать необходимость увеличения ресурсов до возникновения критических ситуаций.
Помните: прежде чем добавлять ресурсы, убедитесь, что текущие используются оптимально. Часто проблему высокой нагрузки можно решить настройкой существующего ПО, а не просто увеличением мощности железа.